並列プログラミング環境
並列処理(parallel processing)とは、複数のプロセッサを用いて、処理を高速化する技術である。RMIやJiniなどの分散処理(distributed processing)は、もちろん、複数のプロセッサを用いるため処理を高速化することもあるが、本質的にはいろいろな場所で行う様々な処理、あるいは機能を結合し、機能分担させることが目的であり、必ずしも高速化だけが目的ではない。したがって、並列処理は高速化が必要な科学技術計算や画像処理などの分野で用いられている。ここで、並列(parallel)と並行(concurrent)という用語について解説しておく。並列処理の「並列」という用語は、「物理的に同時に動作する」ことを意味する。これに対し、「並行」は「論理的に同時に動作する」ことを扱う場合に用いる。たとえば、複数のCPUで同時に処理されているものを制御する場合には「並列」であり、一つのCPUの中でいろいろな処理に対応するサービスを行うオペレーティングシステムは「並行」処理の典型的な例である。
並列計算機システムの形態とプログラミング環境
これまで様々な並列システムが研究されてきたが、典型的な形態として以下の2つに分類される。
l 共有メモリ計算機:複数のCPUが一つのメモリにアクセスするシステム。それぞれのCPUで実行されているプログラム(スレッド)は、メモリ上のデータにお互いにアクセスすることで、データを交換し、動作する。
l 分散メモリ計算機:CPUとメモリという一つの計算機システムが、ネットワークで結合されているシステム。それぞれの計算機で実行されているプログラムはネットワークを通じて、データ(メッセージ)を交換し、動作する。
たとえば、最近、並列処理で広く用いられるようになってきたPCをネットワークで結合したPCクラスタは、分散メモリ計算機の典型的な例である。このためのプログラミング環境としては、メッセージ通信をするための標準ライブラリであるMPI(Message Passing Interface)が一般的に用いられる。大容量のデータを処理するサーバには、共有メモリ計算機が用いられることが多いが、最近ではPCでも2つのプロセッサを持つ共有メモリのものが増えてきた。オペレーティングシステムから提供される基本的な機能を用いるためのライブラリとPOSIX threadライブラリがあるが、さらに高度のプログラミング環境としてOpenMPが用いられるようになってきた。
MPIによるプログラミング
MPIは、分散メモリシステムでは一般的に用いられるようになったメッセージ通信プログラミングのライブラリである。プログラムは、mpirunというコマンドにより、各プロセッサで同じプログラムが起動され、実行が開始される。MPI_Initという関数でライブラリを初期化後、
l MPI_Comm_sizeでプロセッサ数を取得
l MPI_Comm_rankで、0から始まるプロセッサの番号を取得
l MPI_Bcastで、同じメッセージを各プロセッサで送信
l MPI_Sendで、特定のプロセッサでメッセージを送信
l MPI_Recvで、メッセージを受信。
という手順でプログラムする。MPIではCommunicatorという概念が導入されており、プロセッサの関係(トポロジ)を定義することができる。defaultとして最初に与えられるCommuicatorである、MPI_COMM_WORLDは、プロセッサが0からn番まで1次元に並んだ関係を表現している。これは、特に特定の並びを仮定するMPIを用いたライブラリを作成できるようにするために考えられたものである。
ライブラリ関数には、データの各部分をプロセッサに配分するScatter、各プロセッサにあるものを集めてくるgather、データを加算や集計するreduction、飛び飛びにデータを転送するストライド転送など、メッセージ通信のプログラムの典型的なオペレーションが提供されている。
メッセージ通信のプログラムはプログラマがデータのやり取りを逐一記述するもので、直感的であるが、低レベル記述を行うもので、プログラミングに手間がかかる。逐次プログラムを並列プログラムに書き直すために大きなコストを払わなくてはならない。
しかし、現在ではほとんどのすべての分散メモリシステムでサポートされており、MPIで記述しておくことによって、様々な分散メモリシステムでプログラムを動作できるようにした功績は大きい。
分散メモリシステムをターゲットに設計された言語にHPF(High Performance Fortran)があるが、想定した性能がなかなか得られなく、普及にいたっていないのが現状である。
共有メモリの並列プログラミング:OpenMP
共有メモリの計算機ではオペレーティングシステムからのインタフェースとしてPOSIXスレッドライブラリが提供されていることが多い。しかし、このライブラリではスレッド(実行される一連の命令、プロセスのようなもの)の生成、スレッド間の同期(ロック、mutexなど)などの低レベルな機構しか提供されておらず、プログラミングの手間が大きかった。そこで、高レベルのプログラミングモデルであるOpenMPが提案された。
OpenMPは、新しい言語ではなく、CやFotranなどの既存の逐次言語にプラグマ(#pragmaで始まるCの指示文のこと)やコメント行(Fotranでは$!で始まる行)で、指示を加えることにより、OpenMPの並列プログラミングモデルに従ったプログラミングをするための仕様を定めたものである。OpenMPでは以下のような特徴がある。
(1) 既存の逐次プログラムをベースに並列プログラムを作ることができる。
(2) 指示文を使って、スレッドを生成、制御することができ、スレッドライブラリなどを使うよりも簡単にスレッドプログラミングができる。
(3) 徐々に指示文を加えることにより、段階的に並列化をすることができる。
(4) 基本的に、OpenMPの指示文を無視することにより、元の逐次プログラムになります(逐次のsemanticsを保持している)。従って、逐次と並列プログラムを同じソースで管理することができます。
 このような特徴から、MPIのメッセージ通信のプログラミングに比べ非常に簡単に並列化することができる。
このような特徴から、MPIのメッセージ通信のプログラミングに比べ非常に簡単に並列化することができる。
OpenMPの規約では、これらの要素を定義している。
(1)指示文
(2)実行時ルーチン
(3)環境変数
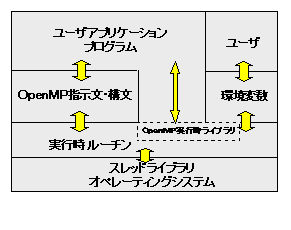
図にOpenMPのアーキテクチャの概略について示しめす。
 OpenMPはこれらの要素を通じて、共有メモリのマルチプロセッサの並列プログラミングモデルを提供している。共有メモリを使ったマルチスレッドプログラミングでは、共有メモリ上でプロセッサによる複数の実行の流れを制御するプログラムを記述する。スレッドとは実行の流れのことで、OpenMPでは、この制御をコンパイラに対する指示文で行う。
OpenMPはこれらの要素を通じて、共有メモリのマルチプロセッサの並列プログラミングモデルを提供している。共有メモリを使ったマルチスレッドプログラミングでは、共有メモリ上でプロセッサによる複数の実行の流れを制御するプログラムを記述する。スレッドとは実行の流れのことで、OpenMPでは、この制御をコンパイラに対する指示文で行う。
OpenMPのプログラムは通常の逐次プログラムと同じようにmainから始まる。#pragmaで始まる行は指示文という。C言語では #pragma omp で始まるプラグマを用いる。
#pragma omp OpenMP指示文 ...
指示文がなければ、通常の逐次プログラムと何ら変わりがない。まず、以下のようなプログラムを考えて見みる
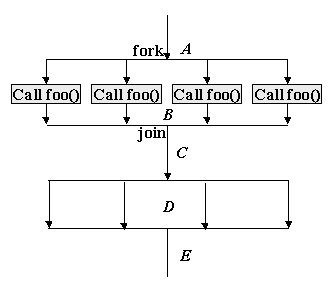
… A ...
#pragma omp parallel
{
foo(); /* ..B... */
}
… C ….
#pragma omp parallel
{
… D …
}
… E ...
Aは通常の逐次プログラムと同じように、実行される。次に、parallel指示文#pragma omp parallelに続くブロック文が複数のスレッドで並列に実行される。このブロック文の実行が終わると、すべてのスレッドの終了を待って、逐次に戻り、Cの部分が逐次に実行される。また、次の#pragma omp parallelがあると、このブロック文が複数のスレッドで実行される。逐次から複数のスレッドになることをfork、1つのスレッドに戻ることをjoinといい、このような実行モデルはfork-joinモデルという。 BやDのparallel指示文があると、この中の文は重複して実行されます。例では、Bの関数呼び出しも含めて、それぞれのスレッドで実行される。parallel指示文で複数のスレッドで実行されるブロックを並列リージョンと呼ぶ。また、この並列リージョンを実行する複数のスレッドのことをteamと呼ぶ。このteam内のスレッドは0から番号がつけられており、元の逐次部分を実行しているスレッドは0番になり、これをマスタースレッドと呼ぶ。
さて、具体的な例を使って説明していくことにする。まずは、Cのプログラムはじめに学習するhello worldのプログラムをOpenMP版を考える。ここではスレッドの番号(すなわち、0から始まるスレッドの番号)を出すことにする。
#include <stdio.h>
main()
{
#pragma omp parallel
{
printf("hello world from %d of %d\n",
omp_get_thread_num(), omp_get_num_threads());
}
}
プログラム中、#pramgaで始まる行はコンパイラに対する指示文である。#で始まっているので通常のCコンパイラにとってはコメント行である。pragmaの後のompキーワードによりOpenMPコンパイラは、このコメント行がコンパイラに対する指示文であると認識する。parallel指示文は、次に続く文あるいはブロックを並列に実行するコードを生成する。
printfでは、OpenMP処理系の実行時ライブラリ関数である、omp_get_thread_num関数およびomp_get_thread_threads関数が呼ばれている。これら関数はそれぞれスレッド番号、スレッドの数を返す関数である。実行すると、#pragma parallel で指定された部分が、それぞれのスレッドで実行され、4CPUのマシンでは、次のような結果が得られる。
hello world from 0 of 4
hello world from 2 of 4
hello world from 1 of 4
hello world from 3 of 4
OpenMPでは並列部分がいくつのスレッドで実行されるのかは、プログラムでは指定しない。通常、共有メモリマシンで実行する場合には何個のCPUがあるかが実行開始時に調べ、そのCPUと同じ数のスレッドが生成、それぞれのCPUでスレッドが実行される。スレッド数を変えたい場合には環境変数OMP_NUM_THREADSで制御する。
ワークシェアリング指示文の使い方:ベクトル計算の並列化
 OpenMPでは、並列リージョンは全てのスレッドで同じコードが実行される。スレッド番号を取得し明示的にマルチスレッドプログラミングをすることもできるが、ワークシェアリング指示文を使うことによって、ループなどを簡単に並列化することができる。ワークシェアリング指示文とは、並列リージョンで、team内のスレッドで指示された文を分割して実行するための指示文である。前に、並列リージョンでは、同じ文を重複して実行すると述べたが、ワークシェアリング指示文のところでは指定された部分を分割して実行する。
OpenMPでは、並列リージョンは全てのスレッドで同じコードが実行される。スレッド番号を取得し明示的にマルチスレッドプログラミングをすることもできるが、ワークシェアリング指示文を使うことによって、ループなどを簡単に並列化することができる。ワークシェアリング指示文とは、並列リージョンで、team内のスレッドで指示された文を分割して実行するための指示文である。前に、並列リージョンでは、同じ文を重複して実行すると述べたが、ワークシェアリング指示文のところでは指定された部分を分割して実行する。
次の例について考えてみる。
int
A[1000];
main()
{
int i;
for(i = 0; i < 1000; i++) A[i]
= i;
printf("sum =
%d\n",sum(A,1000));
}
int
sum(int *a, int n)
{
int s;
s = 0;
for(i = 0; i < n; i++) s
+= a[i];
return s;
}
 関数sumはn個の数を加算する関数である。これを並列化するためには、加算する配列を分割して、各スレッド(CPU)がその部分を加算し、その結果を最終的に合計して、全体の加算をすればよい。
関数sumはn個の数を加算する関数である。これを並列化するためには、加算する配列を分割して、各スレッド(CPU)がその部分を加算し、その結果を最終的に合計して、全体の加算をすればよい。
このようなプログラミングの場合には、for指示文を用いる。for指示文は、ループを並列化するためのワークシェアリング指示文である。
int
sum(int *a, int n)
{
int s;
s = 0;
#pragma
omp parallel
{
#pragma
omp for reduction(+:s)
for(i = 0; i < n; i++) s
+= a[i];
}
return s;
}
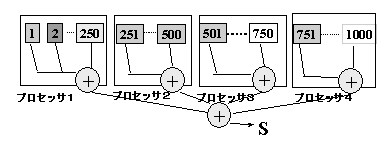
parallel指示文で生成されたスレッドは、for指示文によりforループの各部分を分担して実行する。for指示文は、並列リージョンを実行する複数のスレッドでfor指示文の後にあるループを並列に実行する。例えば、4スレッドで並列実行している場合には、上の例ではiが0から249まではスレッド1, 250から499まではスレッド2、...というように各スレッドで並列に実行します。この場合は均等にあらかじめ分割して実行するが、ループの実行時間がばらつく場合などには動的にループを実行するなど、実行の仕方も指定することができる。
for指示文では、並列実行するループを全てのスレッドがそのループの実行を終了するまで、待ち合せを行う。
並列リージョンに1つのfor指示文で指定される並列ループのみがある場合には、以下のように1つにすることができる。
#pragma
omp parallel for reduction(+:s)
for(i = 0; i < n; i++) s
+= a[i];
この文は、変数sが共有されて加算される変数であることを指示する。このような指示句をデータスコープ属性の指定するものである。
#pragma omp parallel
{
#pragma omp for private(t)
for(i = 0; i < 1000; i++){
t = ...;
...= ... t ...
}
...
}
for指示文の後にあるprivate(t)は、ループ並列実行する場合に変数tをそれぞれのスレッドで別々の変数を持つことを指定するもので、変数データのスコープ属性の指定をするものである。通常、なにも指定しない変数は全てのスレッドで共有される。しかし、例にある変数tのようにループ内で一時的に使われる変数の場合は、private(t)がないと並列実行しているスレッドが同じ変数に書きこんでしまうため、正しく並列化ができなくなる。
データスコープ属性には以下の種類がある。
·
shared(var_list) 構文内で指定された変数がスレッド間で共有される
·
private(var_list) 構文内で指定された変数がprivate
·
firstprivate(var_list) privateと同様であるが、直前の値で初期化される
·
lastprivate(var_list) privateと同様であるが、構文が終了時に逐次実行された場合の最後の値を反映する
· reduction(op:var_list) reductionアクセスをすることを指定、スカラ変数のみ。実行中はprivate、構文終了後に反映
その他の指示文
ワークシェアリング指示文には、ループを並列化するfor指示文の他に、1つのスレッドのみで実行するsingle指示文、異なる部分を別々のスレッドで実行するsection指示文がある。
以下のコードでは、single指示文で指定されたブロック文は一つのスレッドでしか実行されない。
#pragma omp single
{
… statements …
}
この指示文では、すべてのスレッドが到着するまで、待ち合わせを行う。
section指示文では、#pragma omp sectionsで囲まれたブロックのなかで、#pragma omp sectionで指示された部分は別々のスレッドで実行される。これを使っていわゆるタスク並列のプログラミングを行うことができる。
#pragma omp sections
{
#pragma omp section
{ … section1… }
#pragma omp section
{ … section2… }
}
また、この指示文でもすべてのスレッドはこの指示文を実行するまで待ちあわせを行う。
#pragma omp parallelで複数スレッドで実行させる時に、すべてのスレッドを待ち合わせる操作がバリア操作である。この操作を行う指示文がバリア指示文である。
#paramga omp barrier
なお、OpenMPの指示文は複数のスレッドで実行されている場合にしか有効にならない。つまり、#pragma omp parallel で指定される並列リージョン以外では無効になる。(だだし、並列リージョン内から呼び出された関数でも、複数のスレッドで同時に実行されているため、有効になることがある。)