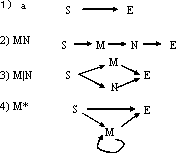
|
字句解析とは、文字列として入力されるプログラムをtokenの列に分解する フェーズである。前回のプログラムにおいて、字句解析を行う関数getTokenは、 文字列を数字(NUM)、演算子(PLUS_OP,MINUS_OP)などのtokenに分けて、返す関 数である。
どのような文字列がどのようなtokenになるかについては、 正規表現 (regular expression) で定義することができる。アル ファベットA上の正規表現とは、
例えば、正規表現a(b|c)*は、最初にaがあり、bまたはcが続く文字列を表 現する。abbcもabcbccも、abccもこの正規表現で表現される文字列である。
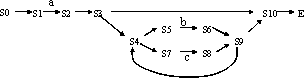
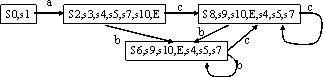
正規表現は、図のような規則で 非決定性有限オートマトン(NDA: nondeterministic finite automaton) に変換できる。 有限オートマトン (finite automaton) とは、有限 の内部状態を持ち、与えられた記号列を読みこ みながら状態遷移し、その記号列があるパターンをもつ列であるかを決定する ものである。非決定性有限オートマトンとは、入力によらない状態遷移(空列 記号に対する状態遷移)をもち、それは非決定的に遷移してもしなくてもよい と状態をもつものである。図にそれぞれの規則に対応するオートマトンを図示 する。
先にあげたa(b|c)*について、この規則で、NDAに変換した結果も示す。
NDAでは、空の状態遷移に対して、状態遷移するかしないかの両方の可能性を しらべなくてはならないので、実際にそのまま実装すると効率がわるい。その ため、非決定的な遷移を取り除き、 決定性有限オートマトン(DFA: deterministic finite automaton) に変換する。DFAとは、以下の条件を満たす 有限オートマトンである。
正規表現が与えられた時に、その言語(文字のパターン)を認識するDFAを機 械的に作り出すことができる。そのアルゴリズムをプログラムにしたものが字 句解析器生成系( lexical analyzer generator)である。このプログラムとし て、有名なのが、lexである。lexでは、定義ファイルは以下の形式でかく。
例えば、a(b|c)*の正規表現を認識する字句解析は、
%{ 任意のCプログラム。定数やCのマクロの宣言をここにかく。 %} 下の定義で使うlexのマクロの定義 %% 正規表現による入力パターンの定義 正規表現パターン アクション という形で書く %% 任意のCプログラム
でよい。
%{ %} %% a(b|c)* { printf("OK\n"); } /*このパターンを入力したらOKを出力する*/ . {printf("NG\n");} /*.は以上以外のパターンの場合のアクションを指定 */ %% /* なにもなし */
これをコンパイルするには、
とする。これでできたa.outを実行すると、abcにたいしてはOK, xxxにはNGと 出力される。Linuxのflexのときには、-llの代わりに、-lflをつかうこと。% lex test.l % cc lex.yy.c -ll
前回示した数式の字句解析の部分は以下のように書ける。
%{ #include "expr.h" %} digit [0-9] /* マクロの定義,digitを0-9の数字の集合と定義する */ %% {digit}+ return NUM; /*0-9の1回以上の繰り返しは、NUMと認識する */ "+" return PLUS_OP; /*+はPLUS_OP +は繰り返しの意味なので、""で囲む*/ "-" return MINUS_OP, /* -はMINUS_OP */ [ \t] /* 空白は無視 */ . printf("error?\n"); /* error */ %% main(){ yystdin = stdout; .... r = yylex(); /* tokenの列はyytextに入る */ printf(" token is %d,'%s'\n",r,yytext); }
lexは、字句解析ルーチンとして、yylexを生成する。このルーチンは、action で指定されたreturn分で返された値を返す。
lexの使い方については、
として、マニュアルを参照のこと。
% man lex